
I’m using Spatie’s Media Library Pro in a project for dgen.net, and ran into a problem when I tried to use a TIFF-format image, and it failed to show a thumbnail of the image:
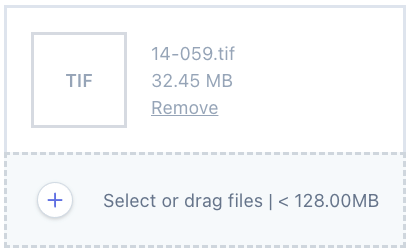
So I set about tracking down why this image didn’t work, since the project this was being used for has lots of TIFF images. This turned into quite the can of worms, but all worked out beautifully in the end.
TIFF images are not supported by most web browsers as they are not a typical “web format”, but they are very common in print and archiving contexts. It doesn’t help that Safari is about the only browser will display them at all, but here the aim is to display a thumbnail, not the actual image, and the thumbnail doesn’t have to use the same format.
Media Library Pro is a set of user interface widgets providing access to Spatie’s Laravel Media Library package, and so it’s dependent on that package to provide all the underlying file management and thumbnail generation, which is handled by a more general mechanism for creating “conversions” of underlying file types. This is especially useful for files that are are not images – for example it’s possible to create thumbnails for audio files using a package I wrote, but being able to do something similar for otherwise undisplayable image types is useful too.
It turns out that Media Library’s image support is handled by yet another Spatie package called (imaginatively) Image. So I started looking there, and found that it did not actually take responsibility for performing image processing operations either, but used yet another package called Glide by the PHP league. In searching for info about using TIFF files with Glide, I found this issue, which told me that Glide already supported TIFF, so long as you were using the imagemagick PHP extension (as opposed to the slower, less capable, but more common GD) as the image processing driver, which I was already. But as I’d seen, this didn’t seem to work. So I set up a simple test script to convert a JPEG image into TIFF using spatie/image (I needed it to convert in both directions), and found that it did indeed create a TIFF file. However, apps I tried could not open it, saying that it was not a TIFF format file. The file command line utility showed me that the file was in fact a JPEG-format image saved with a .tiff extension:
file conversion.tiff
conversion.tiff: JPEG image data, JFIF standard 1.01, aspect ratio, density 1x1, segment length 16, baseline, precision 8, 340x280, components 3Code language: Bash (bash)This was not helpful! So this was a bug in Glide. I tracked down the cause of that and submitted a PR to resolve it.
One general problem with open source projects, is you never know when maintainers are going to get around to merging (or rejecting) PRs, or having merged them, when they will be tagged for release. I know this because I have been guilty of this myself! Here I struck lucky – a maintainer merged it the same day, and also tagged it for release.
Now I had a different problem. This fix was several layers down in my stack of dependencies, and those projects didn’t know about this change in Glide, so if I wanted spatie/image to gain TIFF support, I needed to bump its dependencies to force it to use the new version. It also turned out that while Glide now had TIFF support, Image did not pass that support through to its consumers, so I needed to let it know that TIFF was also a supported format. All that happened in another PR. Spatie has a very good reputation for supporting its open source packages, not least because they constantly dogfood them, and have a great track record of merging PRs quickly and tagging them for release, and this was no exception – my PR was merged and released very quickly.
Now I was nearly there – but not quite! I discovered two almost identical problems in spatie/laravel-media-library and spatie/image: despite delegating image processing functions to their dependencies (i.e. having image say “I support whatever image formats that glide supports”), they both had their own hard-coded list of supported formats. I had already updated this in image in my previous PR, but now I needed to do the same thing (and something similar for tests) for Media Library. Cue PR number 3! True to form, Spatie merged and tagged this release quickly, and my chain was complete! I followed this up with another PR to port my changes to their later version 10 branch (supporting Laravel 9), most of which involved a switch to the pest testing framework.
Finally, back in my app, I bumped my dependency version constraints (so my app picked up the latest versions of these packages), and then I got this:
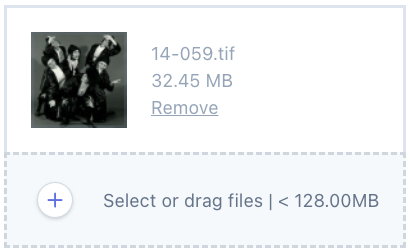
I observed that there’s more that could be done in these packages, in particular that knowing what image formats and MIME types you can support should be limited only at the lowest-level – all higher dependencies should defer to the lower-level packages. This would mean that there is less code to maintain in those packages, and new formats would automatically start working without PR chains like this. So if you have time on your hands… This is of course how a lot of open source software comes into being – there’s always another yak that wants shaving!
This might seem like a lot of effort for a very small feature, but this is how open source works, on its good days! Every package you use is an accumulation of effort by original authors, maintainers, contributors, and reporters, all of whom want to solve one problem or another, and share their efforts so that others can avoid having to solve the same problems all over again.
This particular chain is the longest nested set of PRs I’ve ever done, it was fun to do, was about the first thing I’ve ever “live tweeted”, it resulted in a solution to the specific problem I had, and that solution is now available to all. This is how open source is meant to work, but it’s not always this (remarkably!) smooth. Some package creators can’t be bothered to maintain their packages, others are on holiday, have just had a baby, or have died; raging flamewars erupt over the most trivial things; discrimination (racial, sexual, religious) is unfortunately common; bug reporters often fail to describe their problems well, or make excessive, unrealistic, entitled demands of maintainers. Sometimes this proves to be too much, resulting in great people stopping (or never starting) their participation in the open source ecosystem, which is a terrible shame.
The web would not exist without open source, and if you want to continue to reap the benefits of this beautiful thing we have collectively created, the best way is to support the maintainers. Whether it’s individual developers like me, package creators like Spatie and The PHP League, or open-source juggernauts like Laravel and SensioLabs (Symfony), we can all benefit from support. There are many different ways you can provide support (not just financially), for example making developer time (or other resources) available, paying for products and services sold by companies that back open source projects, paying maintainers, either directly through things like GitHub sponsorship and Patreon, or through broader programmes such as TideLift that might be more acceptable to accounting departments. I’m tooting my own trumpet here (my blog!), but there are literally millions of open source developers out there, and if you’re reading this, you’re using software that we have all created together.










