I was looking back at all the tracks I’ve written and realised that I’d never written one for or about anyone in particular. Then I was thinking of what I’d write in a song like that, and that made me think happy thoughts, of all the nice, kind things I could say, and also all the inside jokes I could use that wouldn’t mean the same to anyone else. So who else to write a song for but my wife? So Sarah, this is for you!
When I think of “happy” songs, I think of Maroon 5, The Lightning Seeds (is “Jollification” the happiest, sweetest album ever??), Jamiroquai, The Feeling, Mark Ronson, Bruno Mars (though I’m not sure “Grenade” is all that happy!), all very much in the mainstream pop/funk genre. So off into the bowels of Logic Pro I go…
For this kind of funky sound, it’s all about up-front bass and drums; Logic’s players are just great at this kind of thing. I started out with a very conventional ii – V – I chord progression in E major using a clean, sharp, jazzy-sounding drum kit and almost no effects on either drums or bass. Next up was something to hold up the middle – a crispy, groovy clav seemed in order, followed by the mandatory funky guitar courtesy of UJAM’s excellent Sparkle 2 virtual guitarist plugin, told to play some chords with a few 9ths sprinkled here and there. The chorus switches to A major, and I think you’d be hard pressed to find more optimistic key changes.
At the same time I’d been thinking about lyrics, and came up with a couple of lines, firstly “You complain that I’m a perv when I compliment those curves“, just because it’s true, closely followed by the title line “you make me smile“. I thought of all kinds of things that were quite inappropriate for a family audience, but I thought I’d leave them out 🤭. I love the line “Let the duvet battle commence“. Towards the end I realised I’d written a line almost straight out of Frankie Valli’s 1967 classic “Can’t take my eyes off you“, so I thought I’d run with it and make it exactly that line, and also found I could borrow the melody used for it too! I also spotted a very close similarity with the Bee Gees “If I can’t have you” from 1990, but avoided going down that particular rabbit hole. Most of the lyrics are quite conventional, but I’m not going to explain the ones that are not (but no, my wife does not have a foot fetish!)
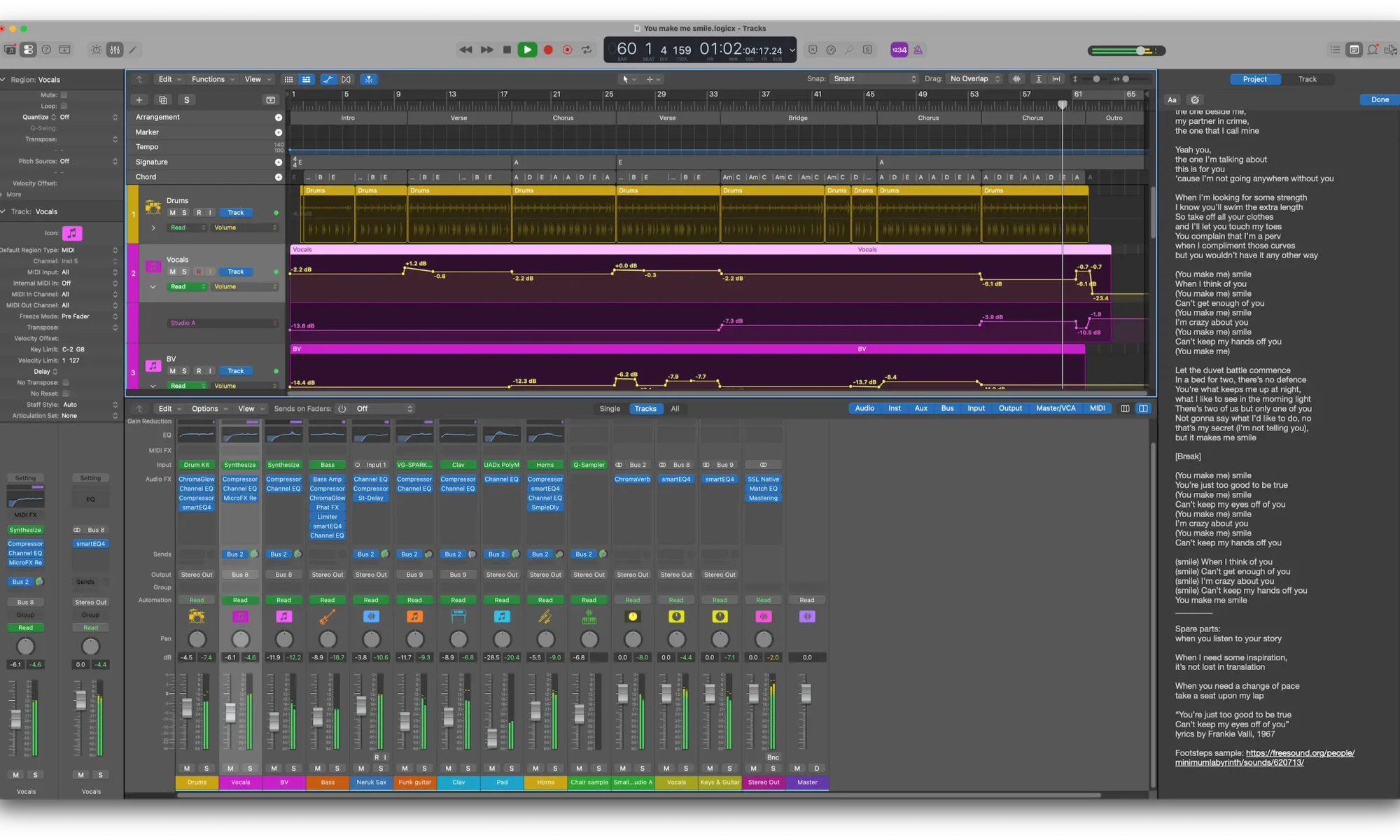
As usual I created the vocals using Synthesizer V, for the first time using the “Liam” voice database. I’d previously ignored this voice, but realised it sounds really great when pushed hard in higher notes, with a great raspy, breathy style when it’s going for it. Some of the timings are quite tricky, so I sang parts of it myself and extracted the timings from that, making it much more natural-sounding. The “that’s our secret” timing took me ages to get right! I used Heavyocity’s MicroFX Refiner plugin on the vocals. While they like to talk about “finesse and extra polish”, it’s really a wonderfully aggressive compressor with great feedback and control.
I love doing backing vocals, here using SV again with my go-to Solaria II voice for both voices. BVs add so much, and this time I got to use unison mode to thicken them up, a feature only recently added to SV that uses multiple voices with minor pitch and timing variations, spread in stereo, driven from a single source track. The lyrics for BVs are so silly — I’ve got “la la la“, “ahhh“, “doo doo doo doo“, and quite a few “oooh, yeah“s — but they’re just such fun.
You can’t really have a funk song without a horn section, so I used Logic’s Studio Horns driven by a Logic player. It took quite a bit of cajoling to stop it from playing too much, but I got there in the end. To fill out the backing a little more in the final double chorus I added a warm, slightly sweepy pad using UA’s PolyMax synth.
Songs are boring if they are all verse and chorus, so I like using a breakdown to make a little space, just as I did in “Call me back“. That space is a great place to drop in a solo, and who can resist a dangling Bsus4 at the end of the break? I commissioned a sax (what else?!) solo from Ukrainian saxophonist Neruk M on Fiverr, whom I chose based on his excellent rendition of the solo from The Beloved’s lovely “Sweet Harmony“, which came out when my wife and I were at university together in 1989. He did a fantastic job, adding real class to my song.
The ending is a little abrupt, so I thought I’d go with the fiction of the singer finishing a take and walking off to do nice things with his wife.
The mix eventually heads through a classic SSL Native Bus Compressor 2, and then to make sure I was on-point, I used a match EQ with Maroon 5’s “Moves like Jagger” as a reference, but found that was really bass heavy, so pulled it back quite a bit. Mastering is through Logic’s built-in mastering chain. I got some good feedback on the Dreamtonics forums that led me to amp up the drums more, especially the kick (TBH I’d not really paid them much attention), and back off the vocals a bit.
Overall, I’m very happy with this song (is any songwriter ever disappointed by their own stuff?), and I don’t think the song could be much more joyful if it tried.
Hey you,
the one beside me,
my partner in crime,
the one that I call mine
Yeah you,
the one I’m talking about
this is for you
‘cause I’m not going anywhere without you
When I’m looking for some strength
I know you’ll swim the extra length
So take off all your clothes
and I’ll let you touch my toes
You complain that I’m a perv
when I compliment those curves
but you wouldn’t have it any other way
(You make me) smile
When I think of you
(You make me) smile
Can’t get enough of you
(You make me) smile
I’m crazy about you
(You make me) smile
Can’t keep my hands off you
(You make me)
Let the duvet battle commence
In a bed for two, there’s no defence
You’re what keeps me up at night,
what I like to see in the morning light
There’s two of us but only one of you
Not gonna say what I’d like to do, no
that’s our secret (I’m not telling you),
and it makes me smile
[Break/Solo]
(You make me) smile
You’re just too good to be true
(You make me) smile
Can’t keep my eyes off of you
(You make me) smile
I’m crazy about you
(You make me) smile
Can’t keep my hands off you
(smile) When I think of you
(smile) Can’t get enough of you
(smile) I’m crazy about you
(smile) Can’t keep my hands off you
You make me smile
I found the sample for the chair/footsteps on freesound.org: Footsteps, pull chair back, sit down, stand up, walk off – Bluebird 219.wav by minimumlabyrinth – License: Creative Commons CC BY Attribution 4.0.
In case you were wondering, there is no AI in this song. We have enough slop from AI without it interfering with nice human things.
I added this song to my “People Music” album, since it’s clearly not a song about web dev! If you like this song, please consider supporting me by buying my albums on Bandcamp, and sharing links to my music on your socials.