
I find it strange to be able to say that I’ve now created several songs that use a synthetic vocalist. This is a somewhat weird concept, but it’s right at the bleeding edge of music technology. We’ve had voice synthesis for years – I remember using a Texas Instruments “Speak & Spell” when I was small in the 1970s, and it’s gradually got better ever since. The first time I ever heard a computer trying to sing (I’m not counting HAL singing “Daisy, Daisy” in “2001”) was in a Mac OS app called VocalWriter, released in 1998, which automated the parameter tweaking abilities of Apple’s stock voice synthesis engine to be able to alter pitch and time well enough for it to be able to sing arbitrary songs from text input. It still sounded like a computer though. A much better “robot singer”, released in 2004, was Vocaloid, but even then, it still sounded like a computer. A Japanese software singer called UTAU, created in 2008, was released under an open source license, and this (apparently) formed the basis of Dreamtonics’ Synthesizer V (SV), which is what I’ve been using. SV finally crosses the threshold of having people believe it’s a real singer.
The entry of my song in the 2024 Fedivision song contest sparked quite a bit of interest. I posted a thread about it on Mastodon, and I wanted to preserve that here too. One commenter said “I thought it was a real person 😅” – which is of course the whole point of the exercise!
SV works standalone, or as a plugin for digital audio workstations (DAWs) such as Apple’s Logic Pro, or Steinberg’s Cubase, and is used much like using any other software instrument. It doesn’t sing automatically; you have to input pitch, timing, and words. Words are split into phonemes via a dictionary, and you can split or extend them across notes, all manually.
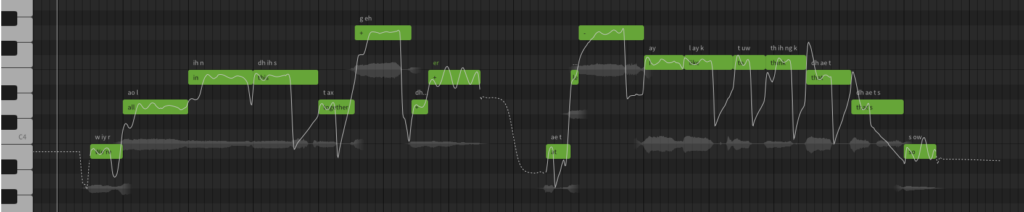
In this “piano roll” editor you can see the original words inside each green note block, the phonemes they have mapped to appear above each note, an audio waveform display below, and the white pitch curve (which can be redrawn manually) that SV has generated from the note and word inputs. You would never guess that’s what singing pitch looks like!
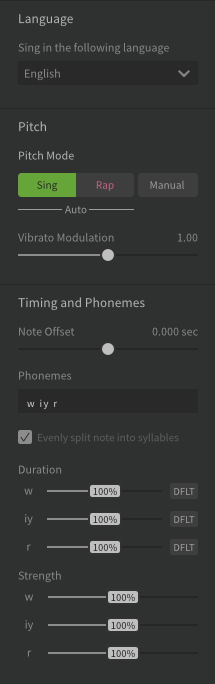
For each note, you have control over emphasis and duration of each phoneme within a word, as well as vibrato on the whole note. This shot shows the controls for the three phonemes in the first word, “we’re”, which are “w”, “iy”, “r”:
This note information is then passed onto the voice itself. The voice is loaded into SV as an external database resource (Dreamtonics sells numerous voice databases); I have the one called “Solaria”. Solaria is modelled on a real person: singer Emma Rowley; it’s not an invented female voice that some faceless LLM might create from stolen resources. You have a great deal of control over the voice, with lots of style options (here showing the “soft” and “airy” modes activated). Different voice databases can have different axes of variation like these; for example a male voice might have a “growly” slider:
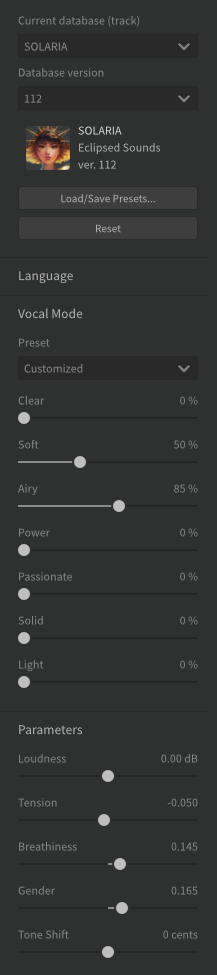
There are lots of other parameters, but most interestingly tension (how stressed it sounds, from harsh and scratchy, to soft and smooth), and breathiness (literally air and breath noise). The gender slider (how woke is that??) is more of a harmonic bias between chipmunk and Groot tones, but the Solaria voice sounds a bit childish at 0, so I’ve biased it in the “male” direction.
The voice parameters can’t be varied over time, but you can have multiple subtracks within the SV editor, each with different settings, including level and pan, all of which turn up pre-mixed as a single (stereo) channel in your DAW’s track:

In my Fedivision song, I used one subtrack for verses, and another for chorus, the chorus one using less breathiness and trading “soft” mode for some “passionate” to make it sound sharper and clearer.
This is still all quite manually controlled though – just like a piano doesn’t play things by itself, you need to drive this vocalist in the right way to make it sound right.
Since the AI boom, numerous other ways of getting synthetic singing have appeared, for example complete song generation by Udio is very impressive, but it’s hard to make it do exactly what you intended; a bit like using ChatGPT. Audimee has a much more useful offering – re-singing existing vocal lines in a different voice. This is great for making harmonies, shifting styles, but only really works well if you already have a good vocal line to start with – and that happens to be something that SV is very good at creating. I’ve only played a little with Audimee; it’s very impressive, but lacks the expressive abilities of SV; voices have little variation in style, emotion, and emphasis, and as a result seem a little flat when used for more than a couple of bars at a time. Dreamtonics have a new product called VocoFlex that promises to do the same kind of thing as Audimee, but in real time.
All this is just progress; we will no doubt see incremental improvements and occasional revolutions, and I look forward to being able to play with it all!
15 Replies to “My synthetic vocalist: Dreamtonics Synthesizer V”